
Google しごと検索にも連携!採用係長をまずは無料で試す
Googleしごと検索への掲載方法は、自社で構造化データを実装する方法だけではありません。ATS(採用管理システム)で採用サイトを作成する方法や、Googleしごと検索に対応した求人サイトを活用する方法もあります。
Googleしごと検索は、Googleに直接求人を投稿するサービスではなく、掲載元の求人ページをGoogleが読み取り、検索結果上の求人枠に表示されることがある仕組みです。構造化データを正しく整えても表示が保証されるわけではないため、掲載方法だけでなく、更新や募集終了時の運用まで含めて整えておくことが大切です。
本記事では、Googleしごと検索の基本的な仕組みから、掲載方法、Indeedとの違い、表示されないときの確認ポイントまでを初心者の方にもわかりやすく解説します。技術対応が難しい場合の代替策もご紹介していますので、自社に合った進め方を見つける参考にしてください。
- Googleしごと検索に求人を掲載する方法は、『自社実装』『ATS』『対応求人サイト』の3つです
- 自社実装では、単一の求人詳細ページにJobPostingを付与し、公開・更新・募集終了まで運用します
- 表示されないときは、本文と構造化データの不一致、期限切れ求人、応募方法の不足を優先して確認しましょう
- Googleしごと検索がどんな仕組みで求人を表示しているのか
- Googleしごと検索に求人を掲載する3つの方法
- Indeedとの違いと、自社に向いている活用パターン
- 構造化データ・Indexing API・表示されない原因などの実務ポイント
- 技術対応が難しい場合に、採用サイト作成ツールを活用する進め方
目次
まずはチェック!Googleしごと検索は自社に向いている?
1つでも当てはまる場合は、本記事の手順に沿ってGoogleしごと検索への掲載を検討してみてください。なお、構造化データのマークアップや更新管理など技術的な対応が難しい場合は『採用係長』のような採用サイト作成ツールを活用すると、公開・修正・応募管理まで進めやすくなります。
Googleしごと検索への掲載方法を比較
Googleしごと検索に求人を掲載する方法は、大きく分けて次の3パターンです。すでに自社採用サイトがあり、社内に実装体制がある場合は自社実装、できるだけ手間をかけずに進めたい場合はATS、まずは外部サイトで露出を増やしたい場合は対応求人サイトの活用が向いています。
| 項目 | 自社で実装する場合 (構造化マークアップ+Indexing API) |
『採用係長』を使う場合 (採用サイトを自動連携) |
対応求人サイトを使う場合 (外部媒体経由で掲載) |
| 初期費用・月額 | 開発会社に依頼する場合は制作費・改修費が発生 自社内で対応できれば工数のみ |
無料プランから利用可 有料プランも求人掲載や管理機能を含めた月額制 |
媒体により異なる 無料掲載枠があるサービスもあれば、掲載課金・期間課金の媒体もある |
| 必要な知識 | HTML / JSON-LD / schema.org / Indexing API など、Web技術の理解が必須 | フォーマットに沿って求人原稿を入力するだけ 技術的な知識は基本不要 |
媒体ルールに沿った求人作成が中心 自社での構造化データ実装は不要 |
| 対応範囲 | Googleしごと検索向けの構造化データ実装・メンテナンスが中心 | Googleしごと検索に加え、求人検索エンジンや求人媒体との自動連携も可能 | 媒体掲載が中心 媒体がGoogleしごと検索に対応していれば掲載経路を増やせる |
| 反映スピード | 実装後はGoogleのクロール待ち Indexing APIを実装すれば更新・停止を比較的速く反映しやすい |
採用係長上で求人を更新すると、連携先にも順次自動反映 運用フローがシンプル |
媒体側の反映タイミングに依存 自社で技術運用しなくても始めやすい |
| 運用工数 | 求人ごとに構造化データの追加・修正が必要 サイト構成変更のたびに技術的なメンテナンスが発生 |
管理画面から求人原稿の一元管理が可能 複数求人・複数拠点の運用でも更新作業をまとめて実施しやすい |
媒体ごとに原稿管理が分かれやすい 複数媒体の併用時は更新漏れに注意 |
| 向いている企業 | ・社内にWebエンジニアがいる ・既存サイトの改修コストを許容できる ・自社で細かくカスタマイズしながら運用したい |
・技術的なことは外に任せたい ・複数媒体に一括掲載したい ・少人数で採用担当を兼務している中小企業・店舗 |
・まずは早く求人露出を増やしたい ・自社採用サイトがまだ整っていない ・媒体の集客力も活用したい |
どの方法を選んでも、Googleに直接求人を投稿するわけではありません。掲載元となる求人ページの情報がきちんと整っていること、そして募集終了時に更新や停止の対応ができることが重要です。
『構造化データやIndexing APIをゼロから実装するのはハードルが高い……』という場合でも、採用係長で採用サイトを作成すれば、技術対応なしでGoogleしごと検索への掲載を目指せるため、初めての企業様でも導入しやすくなります。
Googleしごと検索とは?
Googleしごと検索は、Google検索で求人や転職関連のキーワードが検索された際に、検索結果上に求人情報をまとめて表示する機能です。通常の検索結果とは別に求人専用の表示枠が出ることがあり、求職者はそこから求人を一覧で比較できます。
次の画像は、Googleしごと検索により表示された求人です。
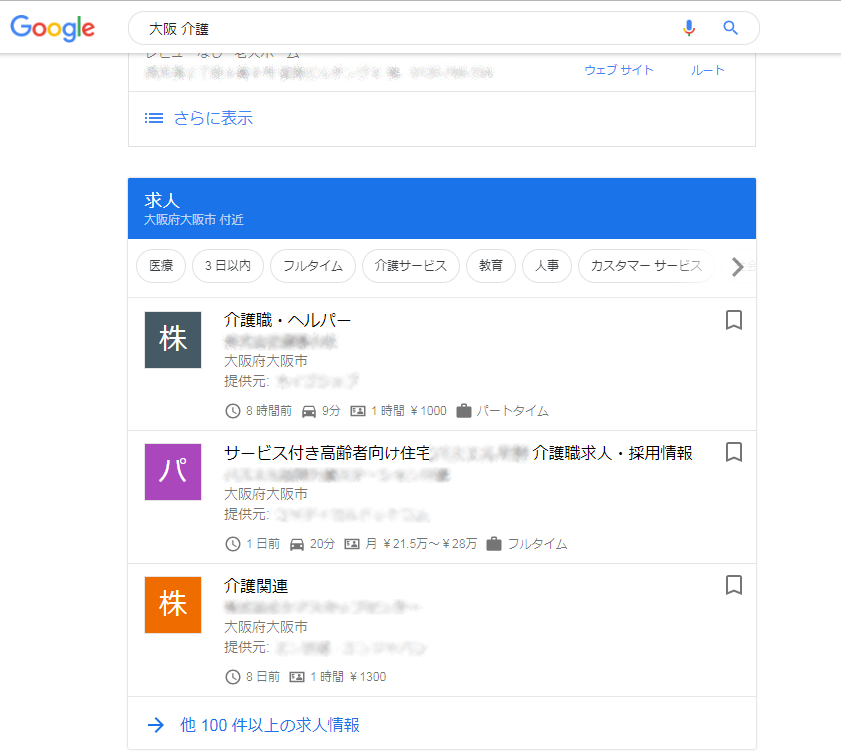
Googleは全世界のあらゆるWebサイトをクロールして、ユーザーが求める情報を検索エンジン上に表示しています。Googleしごと検索は、この仕組みを求人情報にも活用し、求人ページや求人サイトの情報を読み取って、検索キーワードや勤務地などに応じて求人を表示します。
つまり、Googleしごと検索はGoogleに直接求人を投稿するサービスではなく、Web上にある求人情報を収集して見せる仕組みです。求人が表示されたあと、求職者は掲載元の採用サイトや求人サイトへ移動して応募します。
また、構造化データを正しく実装しても、検索キーワード・地域・デバイス・ページ品質などの条件によっては表示されないことがあります。あくまで表示される可能性を高める取り組みとして捉えることが大切です。
特徴の違いはありますが、GoogleでもIndeedと同様に『求人を探すための検索機能』が使えるイメージです。
Googleしごと検索の特徴やメリットは?
Googleしごと検索の特徴や主なメリットは、下記の4つです。
Google検索上で利用できる
Googleしごと検索は、Google検索上で求人関連のキーワードを検索した際に表示される求人向けの機能です。パソコン・スマートフォンの両方で利用されており、求職者は普段の検索行動の延長で求人を探せます。
なお、Googleしごと検索はGoogleの検索結果上で表示される機能であり、Yahoo!など他の検索エンジン上で同じ表示枠がそのまま使えるわけではありません。
通常のオーガニック枠とは別の場所に表示される
Googleの検索結果で上位に表示させたければ、一般的にはSEO対策が欠かせません。
しかし、Googleしごと検索は通常のオーガニック枠とは別の求人表示枠に出ることがあるため、一般的なSEO順位だけで露出が決まるわけではありません。
また、求人自体は求職者の位置情報や検索意図に応じて表示されやすくなるため、自然検索で順位が上がらず苦戦している場合でも、Googleしごと検索であれば、より多くの求職者に見てもらえる可能性があります。
ただし、すべての求人検索で必ず表示されるわけではないので、求人内容の充実や構造化データの整備は重要です。
『距離』で求人を絞り込める
求職者側にとって大きなメリットとしては、希望条件に合わせて求人情報を絞り込める点です。
職種や業種、雇用形態だけでなく、距離でも求人を絞り込めるため、近隣に住む求職者に求人をアピールできます。
距離で絞り込む場合、求職者の自宅から職場がどのくらい離れているかを選択でき、半径2km程度の近距離から広域まで選択範囲を決められます。
このような細かい絞り込み機能があることで、求職者は自分に合う求人を見つけやすくなりますし、企業側も近くに住んでいる求職者に自社の求人を知ってもらいやすくなり、双方にメリットがあります。
流入経路を増やしやすい
Googleしごと検索に掲載されると、これまで自社採用サイトや求人媒体だけでは届かなかった検索ユーザーに求人を見てもらえる可能性があります。
Indeedや求人ボックスなどの求人検索エンジン、通常のSEO流入に加えて、Google検索上の求人表示枠という新しい接点が増えるため、応募母集団の拡大にもつながりやすくなります。
Googleしごと検索掲載にかかる料金・費用の目安
Googleしごと検索への求人掲載料金は『無料』です。
理由の詳細は後述しますが、Googleしごと検索は求人情報を収集してユーザーに見せているだけであり、サイト内に求人を直接掲載するわけではないためです。
逆に言うと、『料金を支払って上位に表示させる』といったアプローチはできません。
また、自社採用サイトや他の求人媒体に掲載された情報が表示されるので、まずはGoogleしごと検索以外で求人掲載を始める必要があります。
そのため、求人掲載自体がこれからなのであれば、その分の費用は別途発生します。
Googleしごと検索以外にも無料で掲載できる求人サイトを知りたい方は、下記の記事をご覧ください。
⇒無料で求人掲載できる求人広告21選!効果を出す方法や無料掲載のメリット・デメリット、有料版との違いを解説
Googleしごと検索の利用がおすすめの企業
Googleしごと検索の特徴やメリットを踏まえて、利用をおすすめできる企業の傾向についてご紹介します。
求人への流入経路を増やしたい企業
Googleは多くの方が利用している検索エンジンであり、Googleしごと検索への掲載は、自社求人の露出を高めるうえで効果的です。
自社への応募を増やすためには、『求人をいかにして見てもらうか』がカギとなります。
流入経路がひとつ増えるだけでも、応募数に良い影響をもたらすでしょう。
お金をかけずに求人を掲載したい企業
Googleしごと検索への求人掲載は費用が一切発生しないので、予算をできるだけ抑えて採用活動を進めたい企業にも向いています。
採用コストを抑えながら求人露出を増やせるのは、企業にとって大きなメリットです。
自社採用ページを持っている企業
Googleしごと検索に求人を掲載させるには、自社採用ページを用意するか、他の求人媒体を利用する必要があります。
このうち、求人媒体は掲載料が発生するうえに、定められた期間で求人掲載が終了することもあるため、低コストで運用したいとお考えの方は、自社の採用ページとの連携がおすすめです。
技術対応をできるだけ簡単に進めたい企業
Googleしごと検索に自社で対応するには、構造化データの実装や更新管理、反映確認などが必要になります。
そのため、社内にWebエンジニアがいない、採用担当者が他業務と兼務している、複数求人をまとめて管理したいといった企業は、採用サイト作成ツールやATSを活用した方が運用しやすいケースが多いです。
Googleしごと検索とIndeed(インディード)の違いは?
企業が無料で求人を掲載するうえで高い人気を集めているサービスに、求人検索エンジンのIndeedがあります。
Googleしごと検索とIndeedを使い分けられるよう、ここでは両者の違いについて解説します。
※関連記事はこちら
⇒Googleしごと検索とIndeedの両方に求人を掲載する方法とは?
IndeedよりもGoogleしごと検索の方が目に留まりやすいケースがある
Googleしごと検索は、Googleの検索画面において、Indeedの通常検索結果よりも上部に表示されるケースがあります。
なぜなら検索画面に表示される順番が、下記画像のとおり『リスティング広告枠』→『Googleしごと検索枠』→『オーガニック枠』となることが多いためです。

GoogleからするとIndeedはあくまでも検索エンジンに出ているWebサイトの一つなので、SEOで1位だとしてもオーガニック枠の一番上に表示されます。
Googleしごと検索は、検索画面でいち早くユーザーの目に入るため、活用次第で多くのアクセスを集めることが可能です。
有料プランや広告枠がなく、無料で掲載できる
Googleしごと検索は、インターネット上の求人情報を収集する『クロール』によって、求人が掲載されます。
そのため、求人掲載にあたって費用は一切発生しません。
Indeedのように有料プランや広告枠などはなく、ユーザーにとって適切と判断された求人が表示される仕組みになっています。
コストをかけずに流入経路をひとつ増やせるため、採用活動費を抑えたい企業にとっても最適です。
直接応募はできない
Googleしごと検索は、インターネット上の求人情報を収集しているだけであり、求人をクリックすると掲載元のリンクに飛ぶ仕組みになっています。
そのため、求職者はGoogleしごと検索の中で直接応募することはできません。
応募したい求人があった場合は、リンク先の求人掲載元で応募する流れになります。
応募者管理機能はない
Googleしごと検索には、応募者に関するデータを確認したり、応募者とやり取りをしたりする機能がありません。
あくまで『求人情報を見てもらう』ための機能です。
応募者を管理したい場合は、掲載元の自社採用サイトや求人媒体、ATSで行う必要があります。
直接求人を投稿できない
Indeedで求人掲載する場合は、クロールのほかに、Indeed内で求人を直接投稿できます。
簡単なフォーマットに沿って項目を埋めるだけで求人投稿できるので、スムーズに募集を始めることが可能です。
しかし、Googleしごと検索の求人掲載方法はクロールのみであり、直接投稿することはできません。
Googleしごと検索に求人を掲載する場合は、自社採用ページを準備するか、他の求人媒体を利用する必要があります。
構造化マークアップが必要
『構造化マークアップ』とは、自社サイトをGoogleしごと検索に読み込んでもらいやすくするために、求人情報を機械が読み取りやすい形式で記述することです。
自社採用サイトをGoogleしごと検索の表示対象にしたい場合は、『この部分は職種名』『この部分は労働時間』のように、サイトに記載されている情報をGoogleのクローラーに理解してもらう必要があります。
そのための作業が、構造化マークアップです。
構造化マークアップには、HTMLやJSON-LDに関する専門的な知識が求められます。
自社での対応が難しい場合は、外部の専門家に依頼することや、採用サイト作成ツールを活用することも解決法のひとつです。
※Indeedの料金体系やメリット・デメリット、効果を出す方法などを知りたい方は、下記ページをご覧ください。
→インディード(Indeed)とは?メリット・デメリット、効果を出す方法まで徹底解説!
Googleしごと検索に求人情報を掲載する方法は?
Googleしごと検索に求人情報を掲載するには、以下の3ステップが必要です。
- 採用ページを作る
- 構造化データをマークアップする
- ページをインデックスさせる
なお、技術対応が難しい場合は、ATSで採用サイトを作成する方法や、Googleしごと検索に対応している求人サイトに掲載する方法もあります。自社実装にこだわりすぎず、運用しやすい方法を選ぶことが大切です。
採用ページを作る
Googleしごと検索に求人情報を登録・掲載するには、採用ページを作成する必要があります。
自社の採用ページがなくても、Googleしごと検索に対応している求人媒体に求人情報が掲載されていれば、求人媒体経由で登録・掲載することが可能です。
しかし、求人媒体は掲載形式やレイアウトが一定のため、自社採用ページよりも掲載できる情報に限りがあります。また、求人媒体は掲載料が発生し、定められた期間で求人掲載が終了する場合もあるため、低コストで運用したいとお考えの方は自社の採用ページとの連携がおすすめです。
採用サイトの作成や複数求人の管理を効率化したい場合は、採用係長のような採用サイト作成ツールを活用する方法もあります。
また、採用ページには、仕事内容・雇用形態・給与・勤務地・勤務時間だけでなく、応募方法や応募先がわかる導線も明記しておきましょう。Googleしごと検索に表示されても、リンク先で応募方法が分からなければ機会損失につながります。
求人情報を構造化データマークアップし、サイトマップをGoogleに送信する
求人情報の構造化データをJSON-LDを用いてマークアップしたイメージです。
JSON-LDは<head>タグ内、または<body>内に記述するのが一般的です。
※求人情報の構造化データはschema.orgのJobPostingを利用します。
- 求人一覧ページではなく、単一の求人詳細ページにJobPostingを付与する
- ページ本文と構造化データの内容を一致させる
- 重複URLがある場合は、canonicalで正規URLを明確にする
- ログインしないと求人詳細が見えないページにはしない
- robots.txtやnoindexで、Googleが求人詳細ページを読めない状態にしない
<script type="application/ld+json">
{
"@context": "https://schema.org/",
"@type": "JobPosting",
"title": "Webコンテンツ・求人広告ライター",
"description": "<p><業務内容></p><p>自社オウンドメディアの記事制作や求人原稿作成を担当します。</p><p>応募資格:学歴・経験不問</p><p>勤務時間:09:00~18:00(時間応相談/シフト制)</p>",
"datePosted": "2023-02-01",
"validThrough": "2023-03-31T23:59",
"employmentType": "FULL_TIME",
"hiringOrganization": {
"@type": "Organization",
"name": "株式会社ネットオン",
"sameAs": "https://neton.co.jp/"
},
"jobLocation": {
"@type": "Place",
"address": {
"@type": "PostalAddress",
"postalCode": "530-0002",
"addressRegion": "大阪府",
"addressLocality": "大阪市北区",
"streetAddress": "曾根崎新地1-1-49 梅田滋賀ビル4F",
"addressCountry": "JP"
}
},
"baseSalary": {
"@type": "MonetaryAmount",
"currency": "JPY",
"value": {
"@type": "QuantitativeValue",
"minValue": 220000,
"maxValue": 450000,
"unitText": "MONTH"
}
},
"workHours": "09:00~18:00(時間応相談/シフト制)"
}
</script>※これらの構造化データマークアップは求人サイトや求人情報により書き方が変わりますので、あくまでもイメージです。
上記の構造化データマークアップでは、『baseSalary』『workHours』といったコードがHTMLを囲むようにマークアップされているのが確認できると思います。
これらのコードにはそれぞれ意味があり、Googleがクロールしたときに情報を正しく読み取れるようにする大切な役割があります。
そして、これらのコードには、入れておかないとGoogleしごと検索の表示対象として認識されにくくなるものがあります。
- title(職種)
- description(求人詳細・募集要項)
- datePosted(投稿日)
- hiringOrganization(募集企業)
- jobLocation(勤務地)
- validThrough(求人の有効期限)※有効期限がある場合のみ必須
- baseSalary(給与)
- employmentType(雇用形態)
- identifier(求人ID)
- jobLocationType(リモート勤務区分)
- applicantLocationRequirements(応募可能地域)
- hiringOrganization.logo(会社ロゴ)
最低限、必須項目をそろえることが重要ですが、給与や雇用形態などの情報もあわせて記述しておくと、求職者にもGoogleにも求人の内容が伝わりやすくなります。
また、titleには装飾的なコピーではなく、できるだけ職種名がそのままわかる表現を使うのがおすすめです。リモート求人では、必要に応じてjobLocationTypeやapplicantLocationRequirementsも活用しましょう。
Indexing APIを導入する
Indexing APIは、求人情報ページの公開・更新・削除をGoogleに通知するための仕組みです。
Googleしごと検索に求人情報を表示するためには、Googleからクロールされる必要がありますが、通常のクロールでは修正内容がすぐに反映されるとは限りません。
そのため、求人情報のURLに変更があれば、Indexing APIで通知しておくと更新・停止の反映を早めやすくなります。
あわせて、サイト全体のカバレッジを補うためにサイトマップも送信しておくと安心です。新規公開や修正を早く伝えたいときはIndexing API、サイト全体を広く把握してもらう補助としてサイトマップ、という形で使い分けると運用しやすくなります。
- 求人一覧ページではなく、求人詳細ページごとに構造化データを設置している
- ページ本文と構造化データの内容が一致している
- 重複URLがある場合はcanonicalを設定している
- 応募方法や応募先がページ内に明記されている
- ログインしないと求人詳細が見えない設計になっていない
- 募集終了後はvalidThroughや掲載状態を更新している
- リッチリザルト テストでエラーや警告を確認している
- URL検査ツールでGoogleから見えるページ状態を確認している
- 公開・更新・削除のタイミングでIndexing APIを活用している
- サイトマップも送信し、求人URLの更新状況を伝えている
求人情報()の構造化データマークアップの手順
マークアップデータを確認する(HTMLソース)
下記の求人情報を例にご説明します。
| 会社名 | 株式会社ネットオン |
| 職種 | WEBコンテンツ・求人広告ライター |
| 業務内容 |
あなたにお任せしたいお仕事は、自社のオウンドメディアや顧客インタビュー記事のライティング及び、採用係長ユーザーの求人広告ライティング業務です。 主に下記のライティングをお任せします。 |
| 求めるスキル・経験 | ・ライティング経験 特に求人メディア、求人原稿のライター経験者、大歓迎♪ |
| 雇用形態 | 正社員 |
| 勤務時間 | 09:00~18:00 (時間応相談/シフト制) [休憩時間] 1時間(12時〜13時) |
| 給与 | 月給¥220,000 ~ ¥450,000(金額応相談) |
| 勤務地 | 〒5300051 大阪府大阪市北区曽根崎新地1-49-1 梅田滋賀ビル4F |
| 求人開始日 | 2023年2月1日 |
| 求人終了予定日 | 2023年3月31日 |
このような求人情報があったとします。
そして、ここからHTMLデータを確認すると、下記のようなHTMLデータが見つかります。
<table>
<tbody>
<tr>
<td>会社名</td>
<td>株式会社ネットオン</td>
</tr>
<tr>
<td>職種</td>
<td>WEBコンテンツ・求人広告ライター</td>
</tr>
<tr>
<td>業務内容</td>
<td>
<p>あなたにお任せしたいお仕事は、自社のオウンドメディアや顧客インタビュー記事のライティング及び、採用係長ユーザーの求人広告ライティング業務です。</p>
<p>主に下記のライティングをお任せします。<br />
——————————————–<br />
・自社のオウンドメディア「採用アカデミー」<br />
・顧客成功事例の取材<br />
<顧客成功事例><br />
https://saiyo-kakaricho.com/voice/<br />
・クライアントの求人原稿<br />
※あなたの希望する働き方をお伝えください!<br />
——————————————–</p>
</td>
</tr>
<tr>
<td>求めるスキル・経験</td>
<td>・ライティング経験<br />
特に求人メディア、求人原稿のライター経験者、大歓迎♪</td>
</tr>
<tr>
<td>雇用形態</td>
<td>正社員</td>
</tr>
<tr>
<td>勤務時間</td>
<td>09:00~18:00 (時間応相談/シフト制)<br />
[休憩時間]<br />
1時間(12時〜13時)</td>
</tr>
<tr>
<td>給与</td>
<td>月給¥220,000 ~ ¥450,000(金額応相談)</td>
</tr>
<tr>
<td>勤務地</td>
<td>〒5300051<br />
大阪府大阪市北区曽根崎新地1-49-1 梅田滋賀ビル4F</td>
</tr>
<tr>
<td>求人開始日</td>
<td>2023年2月1日</td>
</tr>
<tr>
<td>求人終了予定日</td>
<td>2023年3月31日</td>
</tr>
</tbody>
</table>
ここで、どのHTMLがどの部分に当たっているのか確認してみてください。
構造化データの属性を当てはめてマークアップ(マイクロデータを用いてマークアップ)
次に、先ほどのHTMLデータに対して、必要な構造化データのプロパティとタイプをピックアップします。
構造化データ化をする方法はいくつかありますが、『JSON-LD』か『マイクロデータ』を利用する方法のどちらかが主流です。
ただし、Googleは『JSON-LD』での記述を推奨しています。既存サイトの構造によってはマイクロデータの方が実装しやすいこともあるため、ここではマイクロデータの例も紹介します。実務では、更新しやすさや管理のしやすさからJSON-LDを第一候補に考えるとよいでしょう。
■この求人情報に必要な構造化データ
構造化データのピックアップは『https://schema.org/JobPosting』から行います。
| プロパティ | タイプ | |
| 会社名 | hiringOrganization |
会社名とURLです。
|
| 職種 | title | – |
| 業務内容 | description | – |
| 求めるスキル 経験 |
skills | – |
| 雇用形態 | employmentType |
雇用形態は下記から選択
※複数選択も可能 |
| 勤務時間 | workHours | – |
| 給与 | baseSalary | MonetaryAmount minValue maxValue currency value unitTextには、次のいずれかの値(大文字と小文字を区別)を使用
|
| 勤務地 | jobLocation |
|
| 求人開始日 | datePosted | – |
| 求人終了予定日 | validThrough | – |
今回の求人情報に必要な構造化データが分かりました。
では、ここから実際にマークアップしていきます。
■マイクロデータを利用して構造化データマークアップを行ったコード
<div itemscope itemtype="https://schema.org/JobPosting">
<table>
<tbody>
<tr>
<td>会社名</td>
<td itemprop="hiringOrganization" itemscope itemtype="https://schema.org/Organization">
<span itemprop="name">株式会社ネットオン</span>
<meta itemprop="sameAs" content="https://neton.co.jp/" />
</td>
</tr>
<tr>
<td>職種</td>
<td><span itemprop="title">WEBコンテンツ・求人広告ライター</span></td>
</tr>
<tr>
<td>業務内容</td>
<td><span itemprop="description">あなたにお任せしたいお仕事は、自社のオウンドメディアや顧客インタビュー記事のライティング及び、採用係長ユーザーの求人広告ライティング業務です。</span></td>
</tr>
<tr>
<td>求めるスキル・経験</td>
<td><span itemprop="skills">ライティング経験</span></td>
</tr>
<tr>
<td>雇用形態</td>
<td><span itemprop="employmentType">FULL_TIME</span></td>
</tr>
<tr>
<td>勤務時間</td>
<td><span itemprop="workHours">09:00~18:00(時間応相談/シフト制)</span></td>
</tr>
<tr>
<td>給与</td>
<td itemprop="baseSalary" itemscope itemtype="https://schema.org/MonetaryAmount">
<meta itemprop="currency" content="JPY" />
<span itemprop="value" itemscope itemtype="https://schema.org/QuantitativeValue">
<meta itemprop="minValue" content="220000" />
<meta itemprop="maxValue" content="450000" />
<meta itemprop="unitText" content="MONTH" />
月給¥220,000 ~ ¥450,000(金額応相談)
</span>
</td>
</tr>
<tr>
<td>勤務地</td>
<td itemprop="jobLocation" itemscope itemtype="https://schema.org/Place">
<span itemprop="address" itemscope itemtype="https://schema.org/PostalAddress">
<span itemprop="postalCode">5300051</span>
<span itemprop="addressRegion">大阪府</span>
<span itemprop="addressLocality">大阪市北区</span>
<span itemprop="streetAddress">曽根崎新地1-49-1 梅田滋賀ビル4F</span>
<meta itemprop="addressCountry" content="JP" />
</span>
</td>
</tr>
<tr>
<td>求人開始日</td>
<td><span itemprop="datePosted">2023-02-01</span></td>
</tr>
<tr>
<td>求人終了予定日</td>
<td><span itemprop="validThrough">2023-03-31T23:59</span></td>
</tr>
</tbody>
</table>
</div>このようにマイクロデータを利用することで、ウェブサイトのHTMLコードと共存させながら指定できます。
ウェブサイトの構造によっては、このようにHTML部分に記載する方が簡単な場合もあります。
一方で、現在はJSON-LDでの実装を選ぶケースも多いため、既存のサイト構成や更新しやすさも踏まえて選ぶとよいでしょう。
Googleしごと検索に求人を掲載する際の注意点
Googleしごと検索は、無料で求人が掲載される便利な機能ですが、コンテンツポリシーに違反していると求人が表示されません。
実際にGoogleでは、求人情報に適用されるポリシーとして、下記の内容を違反としています。
| ・求人とは関係のない情報 ・説明が不十分な求人情報 ・応募者を騙そうとする、あるいは誤解を与える情報 ・冒とく的な表現を用いた求人情報 ・求人情報を装った広告(アフィリエイトなど) ・法律に違反している求人情報 ・期限切れの求人情報 ・応募方法が示されていない求人情報 ・募集していない求人情報 ・求人の要件が明記されていない求人情報 ・応募者から金銭を求める求人情報 ・ログインしないと詳細が見えない求人情報 ・求人一覧ページや検索結果ページに個別求人のJobPostingを付与すること |
コンテンツポリシーに違反した場合、Googleの求人検索自体から自社の求人情報が削除される可能性もあるため、十分に注意してください。
なお、掲載基準を満たしていても、Googleしごと検索への表示が必ず保証されるわけではありません。表示されない場合は、実装ミスだけでなく、求人内容の不足や更新遅れもあわせて確認することが大切です。
- 求人詳細ページに構造化データが入っているか
- 求人一覧ページや検索結果ページにJobPostingを付けていないか
- ページ上の内容と構造化データの値が一致しているか
- 募集終了後の求人が公開されたままになっていないか
- validThroughの期限が切れていないか
- 応募方法・勤務地・仕事内容などが不足していないか
- 重複URLがある場合にcanonicalが正しく設定されているか
- ログイン必須、robots.txt、noindexなどでGoogleが詳細ページを読めない状態になっていないか
- リッチリザルト テストでエラーが出ていないか
- URL検査ツールでレンダリング後のページ状態を確認したか
- Search Consoleでリッチリザルトの状態や手動対策の有無を確認したか
- 更新後にIndexing APIやサイトマップ送信でクロールを促しているか
構造化データの実装や更新運用が難しい場合は、採用サイト作成から応募管理までまとめて進められる方法を選ぶのも有効です。
⇒『採用係長』をまずは無料で試す
※Googleしごと検索に求人が表示されない場合の対応方法は、下記ページで解説しています。
→Googleしごと検索に表示されない原因は?対応方法もあわせて徹底解説
Googleしごと検索に関するよくある質問
Googleしごと検索への掲載は本当に無料ですか?
Googleしごと検索自体への掲載費用は無料です。
ただし、自社採用サイトの制作・改修費、ATSの利用料、求人媒体の掲載料など、掲載元を用意するための費用は別途発生する場合があります。
Googleしごと検索に直接求人を投稿できますか?
できません。Googleしごと検索は、Web上にある求人情報を収集して表示する仕組みです。
自社採用サイト、ATSで作成した求人ページ、Googleしごと検索に対応している求人サイトなどに求人を掲載したうえで、Googleに読み取ってもらう必要があります。
構造化データを入れれば必ず表示されますか?
必ず表示されるわけではありません。構造化データはGoogleしごと検索の表示対象になる可能性を高めるためのもので、検索条件や地域、ページ品質などによって表示有無は変わります。
ただし、構造化データがない、またはページ内容と一致していない場合は表示されにくくなるため、まずは基本要件を正しく整えることが重要です。
Googleしごと検索にはどのくらいで反映されますか?
公開後や更新後にすぐ反映されるとは限りません。Googleのクロール状況やページ品質にも左右されます。
更新を反映させやすくするためには、構造化データの整備に加え、Indexing APIで更新や削除を通知し、サイトマップでもサイト全体の更新を伝える運用がおすすめです。
求人一覧ページにまとめてJobPostingを入れてもよいですか?
おすすめできません。JobPostingは、求人一覧ページではなく、1件の求人内容が読める求人詳細ページに付与するのが基本です。
一覧ページや検索結果ページに個別求人の構造化データを入れると、ポリシー違反になる可能性があります。
表示されないときは、まず何を確認すればよいですか?
まずは、求人詳細ページに構造化データが正しく入っているか、ページ内容と構造化データが一致しているか、募集終了後の求人が残っていないかを確認してください。
また、応募方法の記載漏れ、canonicalの設定漏れ、ログイン必須ページ、リッチリザルト テストでのエラーも見落としやすいポイントです。
募集終了した求人はどう処理すればよいですか?
募集終了後は放置せず、validThroughを過去日にする、ページを404/410にする、JobPostingを削除するなどの対応が必要です。
あわせてIndexing APIで削除や更新を通知しておくと、情報の反映を早めやすくなります。
リモート求人はどう記述すればよいですか?
在宅勤務やフルリモートの求人では、必要に応じてjobLocationTypeやapplicantLocationRequirementsを設定します。
たとえば『全国から応募可能』なのか、『特定の都道府県からのみ応募可能』なのかが分かるようにしておくと、求職者にもGoogleにも伝わりやすくなります。
構造化データの実装が難しい場合はどうすればよいですか?
自社での実装が難しい場合は、ATSで採用サイトを作成する方法や、Googleしごと検索に対応している求人サイトを活用する方法があります。
技術対応の負担を減らしながらGoogleしごと検索への掲載を目指したい場合は、採用係長のような採用サイト作成ツールを使うと運用しやすくなります。
IndeedとGoogleしごと検索は併用できますか?
はい、併用できます。どちらも求人露出を増やす手段として相性がよく、応募導線を増やしたい企業に向いています。
併用方法を詳しく知りたい方は、Googleしごと検索とIndeedの両方に求人を掲載する方法とは?もあわせてご覧ください。
まとめ
Googleしごと検索に求人情報を表示させるには、基本的に構造化データマークアップが必要です。
そして、構造化データマークアップをする方法は2種類あります。
- マイクロデータ
- JSON-LD
実務ではJSON-LDが推奨されますが、既存サイトの構造によってはマイクロデータが実装しやすい場合もあります。どちらのやり方で行うにしても、単一の求人詳細ページに必要な情報をそろえ、ページ本文との内容を一致させることが重要です。
また、自社実装だけでなく、採用サイト作成ツールやATSを使って採用ページを作る方法、Googleしごと検索に対応した求人サイトに掲載する方法もあります。
いずれの方法でも、必須項目を入れることに加え、給与・雇用形態・ロゴ・勤務地などの情報もできるだけ明記しておくと、求人情報が伝わりやすくなります。
公開後は、リッチリザルト テスト、URL検査ツール、Search Consoleで状態を確認しながら、更新や募集終了時にはIndexing APIとサイトマップで最新情報を伝えていきましょう。
Googleしごと検索に掲載できれば、このように表示されます。
なお、採用サイト作成ツール『採用係長』で採用ページを作成すれば、技術的な対応不要でGoogleしごと検索への掲載を目指せます(Googleしごと検索の掲載基準は満たしている必要があります)。無料から試すことができるので、まずは自社に合う運用かどうかを確認してみてください。
求人広告を掲載したい方へ
採用係長は最大5つの求人検索エンジン(求人ボックス、Googleしごと検索、スタンバイ、Career jet、キュウサク)にワンクリックで連携できます。ぜひ一度お試しくださいませ。
採用係長とは?
「採用係長」は採用ブランディングから採用プロモーションまで採用業務全般を支援する
「採用マーケティングツール」です。

採用サイトの作成が
誰でも簡単に!

求人検索エンジン
最大5つへ一括連携!

応募者情報を
まとめて一括管理!
採用係長について知りたい方はこちらから
https://saiyo-kakaricho.com/同じカテゴリ内の人気記事
公務員として4年間、人事労務の実務経験あり。 これまで100名以上の事業者をインタビューしており、「企業や個人事業主が本当に悩んでいること」を解決できる記事を執筆します。
ネットオン創業期に入社後、現在は取締役CTOとしてマーケティングからプロダクトまでを統括。
通算約200社のデジタルマーケティングコンサルタントを経験し、Indeed・求人ボックス・スタンバイなどの求人検索エンジンを活用した採用支援を強みとする。特に難しいとされる、飲食や介護の正社員の応募単価を5万円台から1万円台に下げる実績を持つ。
求人検索エンジンを活用した採用集客や、Google Analytics等の解析ツールを用いた効果分析・サイト改善を強みとしている。